工礦自動化投稿論文格式參考:基于深度學(xué)習(xí)的煤礦井下人員不安全行為檢測與識別
關(guān)鍵詞:井下不安全行為識別;目標(biāo)檢測;深度學(xué)習(xí);自注意力機(jī)制;YOLOv5s;高分辨率特征提取網(wǎng)絡(luò);時空圖卷積網(wǎng)絡(luò)
作者:郭孝園;朱美強(qiáng);田軍;朱貝貝
作者單位:中煤科工集團(tuán)常州研究院有限公司; 天地(常州)自動化股份有限公司;中國礦業(yè)大學(xué) 信息與控制工程學(xué)院
摘要:針對井下目標(biāo)發(fā)生多尺度變化、運動目標(biāo)遮擋及目標(biāo)與環(huán)境過于相似等問題,提出了一種基于深度學(xué) 習(xí)的煤礦井下人員不安全行為檢測與識別方法。采用自上而下的策略,構(gòu)建了一種基于自注意力機(jī)制的目標(biāo)檢 測 模 型 YOLOv5s_swin: 在 基 于 自 注 意 力 機(jī) 制 的 模 型 Transformer 基 礎(chǔ) 上 引 入 滑 動 窗 口 操 作 , 得 到 Swin−Transformer,再利用 Swin−Transformer 對傳統(tǒng) YOLOv5s 模型進(jìn)行改進(jìn),得到 YOLOv5s_swin。針對井下人 員與監(jiān)控探頭間距不定導(dǎo)致的人體檢測框多尺度變化問題,在檢測出人員目標(biāo)的基礎(chǔ)上,使用高分辨率特征提取 網(wǎng) 絡(luò) 對 人 體 的 關(guān) 節(jié) 點 進(jìn) 行 提 取 , 再 通 過 時 空 圖 卷 積 網(wǎng) 絡(luò) (ST−GCN) 進(jìn) 行 行 為 識 別 。 實 驗 結(jié) 果 表 明 : YOLOv5s_swin 的精確度達(dá) 98.9%,在 YOLOv5s 的基礎(chǔ)上提升了 1.5%,推理速度達(dá) 102 幀/s,滿足實時性檢測要 求;高分辨率特征提取網(wǎng)絡(luò)能夠準(zhǔn)確提取不同尺度的目標(biāo)人體關(guān)節(jié)點,特征通道數(shù)更多的 HRNet_w48 網(wǎng)絡(luò)性能 優(yōu)于 HRNet_w32;在復(fù)雜工礦條件下,ST−GCN 模型的準(zhǔn)確率和召回率都較高,可準(zhǔn)確地對礦工行為進(jìn)行分類, 推理速度達(dá) 31幀/s,滿足井下監(jiān)測需求。
0 引言
煤礦安全事故中,超過八成是由生產(chǎn)人員的不 安全行為所引發(fā)[1]。因此,對井下人員的行為規(guī)范 進(jìn)行及時且有效的監(jiān)管顯得尤為重要。目前,煤礦 主要是通過監(jiān)控視頻對井下人員的實時行為進(jìn)行人 工監(jiān)控[2-3]。這種方式易導(dǎo)致因個人主觀意識疲憊而 出現(xiàn)漏檢的情況,且配備大量攝像機(jī)也會造成資源 浪費。如何利用監(jiān)控手段實時準(zhǔn)確地識別井下人員 的不安全行為是一個亟待解決的問題。
早期基于圖像的人類行為識別主要是通過對單 個圖像進(jìn)行特征提取實現(xiàn)的[4-5]。但該方式忽略了連 續(xù)動作之間的相關(guān)性,難以準(zhǔn)確描述復(fù)雜動作且識 別準(zhǔn)確率普遍不高。隨后,越來越多學(xué)者專注于利 用視頻流進(jìn)行人員行為識別,主要包括基于雙流卷 積神經(jīng)網(wǎng)絡(luò)[6-9]和基于長短期記憶(LongShort-Term Memory,LSTM)網(wǎng)絡(luò)[10-11]的方法。由于煤礦環(huán)境中 粉塵和光照的影響及人體遮擋等問題,上述方法無 法準(zhǔn)確有效地識別井下人員的行為。利用人體關(guān)節(jié) 信息進(jìn)行行為識別可大大減少環(huán)境等因素的干擾。 因此,部分學(xué)者提出了基于人體關(guān)節(jié)信息的人員行為 識別方法,利用姿態(tài)估計方法檢測人體關(guān)節(jié)信息, 再將該信息輸入圖卷積網(wǎng)絡(luò)(Graph Convolutional Networks,GCN)進(jìn)行分類[12-14]。文獻(xiàn)[15]設(shè)計了一種 時空圖卷積網(wǎng)絡(luò)(SpatialTemporalGraphConvolutional Networks,ST−GCN),開創(chuàng)性地提出了時空圖的概 念,通過將人體骨架序列建模為一個同時包含空間 和時間維度的無向圖,有效處理關(guān)節(jié)信息在空間距 離和時間方向上的變化情況。文獻(xiàn)[16]提出了注意 力增強(qiáng)圖卷積 LSTM 網(wǎng)絡(luò)(AttentionEnhancedGraph ConvolutionalLSTM, AGC−LSTM) ,首次將圖卷積 與 LSTM 結(jié)合并應(yīng)用在基于人體關(guān)節(jié)的行為識別 上。AGC−LSTM 不僅能夠很好地捕獲關(guān)節(jié)信息的 空間和時間特征,還能探索其在空間和時間域的關(guān) 系,為理解人體關(guān)節(jié)信息的復(fù)雜變化情況提供了支 持。文獻(xiàn)[17]提出了雙流自適應(yīng)圖卷積神經(jīng)網(wǎng)絡(luò) (Two-Stream Adaptive Graph Convolutional Networks, 2S−AGCN),將基于自注意力機(jī)制的鄰接矩陣與根據(jù) 人體關(guān)節(jié)物理結(jié)構(gòu)預(yù)先定義的鄰接矩陣相加,表達(dá) 人體關(guān)節(jié)點之間的關(guān)系。文獻(xiàn)[18]提出了語義引導(dǎo) 神經(jīng)網(wǎng)絡(luò),將語義信息和動力學(xué)結(jié)合完成行為識別 任務(wù),通過語義引導(dǎo)增強(qiáng)節(jié)點的特征表達(dá)能力。
煤礦井下全天候使用燈光照明,空氣中充滿煤 灰、粉塵等,導(dǎo)致井下視頻圖像亮度低、背景與目標(biāo) 難以區(qū)分等問題。井下設(shè)備繁多且形狀各異,大多 數(shù)設(shè)備與工裝的顏色相近,給人體位置檢測帶來較 大干擾,影響后續(xù)人員行為識別。同時,由于井下作 業(yè)空間有限,監(jiān)控攝像機(jī)大多安裝在井下人員活動 空間的斜上方,監(jiān)控視角所覆蓋的巷道大多呈現(xiàn)狹 長狀態(tài),運動目標(biāo)在遠(yuǎn)近距離的活動過程中,攝像機(jī) 捕獲到的目標(biāo)尺度不斷變化,運動目標(biāo)離攝像機(jī)越遠(yuǎn), 目標(biāo)在捕獲的畫面中所占像素比越小,井下視頻中 目標(biāo)的這種特殊性給行人檢測及行為識別帶來很大 困難。
針對井下目標(biāo)發(fā)生多尺度變化、運動目標(biāo)遮擋 及目標(biāo)與環(huán)境過于相似等問題,本文提出了一種基 于深度學(xué)習(xí)的煤礦井下人員不安全行為檢測與識別 方法,通過對井下人員進(jìn)行目標(biāo)檢測、姿態(tài)估計和行 為識別,分析井下人員行為是否符合規(guī)定,并可在目 標(biāo)人員出現(xiàn)不安全行為時進(jìn)行報警提示指導(dǎo)。
1 方法架構(gòu)與數(shù)據(jù)集
1.1 方法架構(gòu)
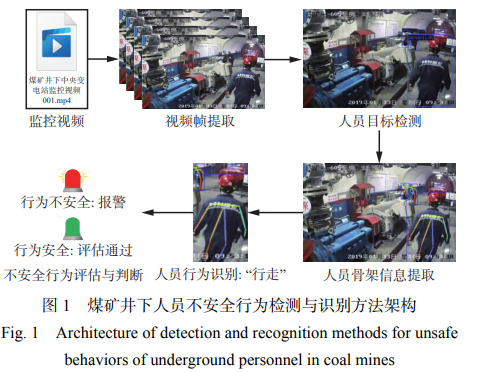
基于深度學(xué)習(xí)的煤礦井下人員不安全行為檢測 與識別方法架構(gòu)如圖 1 所示。首先,獲取煤礦井下 監(jiān)控視頻流數(shù)據(jù),并提取視頻幀圖像。其次,利用基 于注意力機(jī)制的目標(biāo)檢測方法提取視頻幀圖像中的 人員目標(biāo)并標(biāo)記位置,避免將背景設(shè)備等其他物體 誤檢成人員。然后,對檢測到的人員目標(biāo)進(jìn)行骨骼 關(guān)鍵點特征提取,以生成人員整體骨架信息。最后, 利用基于姿態(tài)估計的井下人員行為識別方法分析人員骨架的位置和狀態(tài),得出人員實時行為信息,并對 其行為進(jìn)行安全評估和判斷。
1.2 數(shù)據(jù)集
1.2.1 井下人員檢測數(shù)據(jù)集
從中央變電站、巷道、選煤廠和泵房等關(guān)鍵場景 采集視頻,將視頻進(jìn)行切幀處理,每隔 20 幀提取 1 張圖像,最終生成 2200 張原始圖像。在此基礎(chǔ) 上,運用圖像增強(qiáng)技術(shù)(縮放、翻轉(zhuǎn)、隨機(jī)裁剪和高 斯模糊)對原始圖像進(jìn)行擴(kuò)增,生成 4000 張增強(qiáng)圖 像。經(jīng)過整合,數(shù)據(jù)集中共計 6200 張圖像。鑒于本 研究的目標(biāo)是井下人員,數(shù)據(jù)集中僅標(biāo)注了 1 個類 別,即使用 LabelImg 軟件對圖像中的人體進(jìn)行標(biāo)注, 標(biāo)注標(biāo)簽為“person”。部分?jǐn)?shù)據(jù)集圖像如圖 2 所示。

1.2.2 人員姿態(tài)估計數(shù)據(jù)集
對于人員姿態(tài)估計數(shù)據(jù)集,選用公共數(shù)據(jù)集 MS COCO 來訓(xùn)練人體關(guān)節(jié)點提取模型。MSCOCO 姿 態(tài)估計數(shù)據(jù)集中將人體關(guān)節(jié)點表示為 17 個關(guān)節(jié)點, 關(guān)節(jié)點的具體標(biāo)簽和名稱見表 1。由于環(huán)境與目標(biāo) 人體的遮擋,導(dǎo)致每張圖像中標(biāo)注的樣本關(guān)節(jié)點個 數(shù)不同,當(dāng)樣本中關(guān)節(jié)點個數(shù)過少時,關(guān)節(jié)點之間關(guān) 聯(lián)信息減少,影響姿態(tài)估計網(wǎng)絡(luò)對骨架信息提取的 準(zhǔn)確度;而關(guān)節(jié)點個數(shù)過多時,會增加數(shù)據(jù)集的復(fù)雜 性。為了更好地適應(yīng)煤礦井下圖像中人體關(guān)節(jié)點的 特征提取,選取關(guān)節(jié)點個數(shù)為 10~15 的樣本作為訓(xùn) 練數(shù)據(jù)集,模擬井下環(huán)境對人體關(guān)節(jié)點檢測的影響, 數(shù)據(jù)集共包 括 35000 張圖像。

1.2.3 人員行為識別數(shù)據(jù)集
人員行為識別數(shù)據(jù)集同樣由煤礦監(jiān)控攝像機(jī)拍 攝的視頻圖像構(gòu)成。為了保證數(shù)據(jù)集的多樣性,監(jiān) 控場景主要選取地面的帶式輸送機(jī)運輸區(qū)、物料搬 運庫房及井下的中央變電站、巷道和泵房等區(qū)域。 將采集的視頻按照 20 幀間隔進(jìn)行切分提取,最終生 成了 3200 張原始圖像,主要包括人員的行走、跑 步、倒地與摘安全帽等行為,每種行為分別包含 800 張原始圖像。需要說明的是,除了人員行走與跑 步動作外,其余行為均是在確保相對安全的情況下, 安排具體人員在實際工礦場景模擬的,以保證人員 行為準(zhǔn)確有效。使用 LabelImg 軟件對數(shù)據(jù)集中的 人員動作進(jìn)行標(biāo)注,對應(yīng)上述行為的標(biāo)簽分別為 “walking”“running”“falling”“detaching”,部分?jǐn)?shù)據(jù) 集圖像如 圖 3 所示。
2 基于自注意力機(jī)制的目標(biāo)檢測
利用人體關(guān)節(jié)信息進(jìn)行行為識別的方法通常可 分為自上而下和自下而上 2 種[19]。自上而下的方法 首先使用檢測器對圖像中的人體目標(biāo)進(jìn)行檢測,并 將其單獨框選,再對各人體框進(jìn)行單獨姿態(tài)估計和 行為識別。自下而上的姿態(tài)估計方法則是先檢測并 定位被測圖像中所有存在的人體關(guān)節(jié)點,然后通過 關(guān)節(jié)連接器將這些關(guān)節(jié)點分組匹配至不同目標(biāo),實 現(xiàn)人體關(guān)節(jié)信息提取。對關(guān)節(jié)點的分組匹配過程通 常涉及大量超參數(shù),使得訓(xùn)練過程復(fù)雜[20]。因此,本 文采用自上而下的策略,構(gòu)建一種基于自注意力機(jī) 制的目標(biāo)檢測模型,以更加準(zhǔn)確、高效地提取人體關(guān) 節(jié)信息。
2.1 自注意力機(jī)制原理
自注意力機(jī)制最初被廣泛應(yīng)用在自然語言處理 (NaturalLanguageProcessing,NLP)領(lǐng)域,是一種基于 自注意力計算的深度神經(jīng)網(wǎng)絡(luò)[21-22]。與其他注意力 機(jī)制不同的是,自注意力機(jī)制內(nèi)部進(jìn)行注意力計算 的對象來源相同,例如可以是同一句話中的不同單 詞或者同一張圖像中不同的像素塊。在處理圖像 時,網(wǎng)絡(luò)將圖像劃分成一定的像素塊,通過計算不同 像素塊之間的相關(guān)性來提高檢測精度。
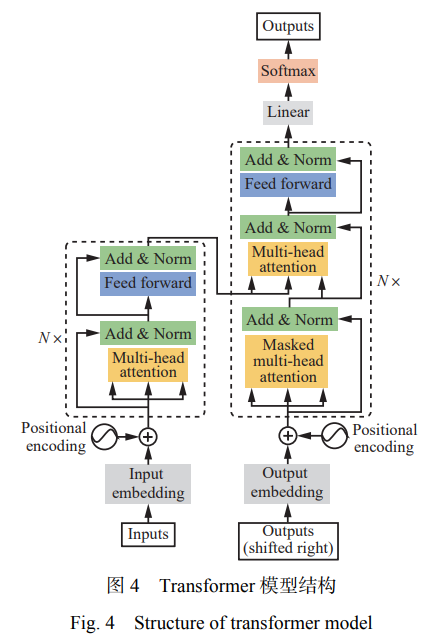
Transformer 是基于自注意力機(jī)制的模型,具有 強(qiáng)大的并行編碼能力[23]。Transformer 模型結(jié)構(gòu)如 圖 4 所示,由 N 個編碼器和 N 個解碼器堆疊而成,能 夠處理不同的像素塊輸入。每個編碼器內(nèi)部包含多 頭注意力層(Multi-headattention) 、前饋神經(jīng)(Feed forward network) 網(wǎng) 絡(luò) 、 殘 差 連 接 (Residual connection) 及 層 歸 一 化 (Layer normalization) 等 組 件。每個解碼器由帶掩碼的多頭注意力層(Masked multi-headattention) 、多頭注意力層、前饋神經(jīng)網(wǎng) 絡(luò)、殘差連接及層歸一化等模塊構(gòu)成。
自注意力機(jī)制通過矩陣運算將每個輸入的像素 塊映射到 3 個不同的空間向量矩陣,分別為查詢矩 陣 Q、鍵矩陣 K 和值矩陣 V:
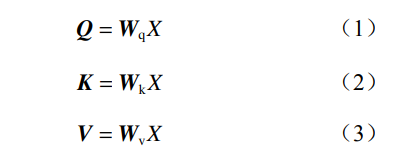
式中:Wq,Wk,Wv 分別為 Q,K,V 的權(quán)重矩陣;X 為輸 入序列數(shù)據(jù)。
自注意力 Attention 的計算公式為
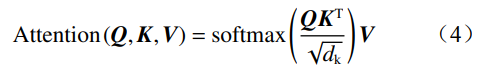
式中 dk 為 Q,K 的列數(shù),即向量維度。
將 Q 和轉(zhuǎn)置后的 K 做點乘,計算 2 個向量之間 的相似度得分,再將相似度得分除以縮放因子 , 將得到的結(jié)果經(jīng)過 softmax 函數(shù),再與 V 相乘,得到 包含當(dāng)前像素塊與其他像素塊間相關(guān)性的特征向 量。對輸入的每個像素塊都進(jìn)行相同操作,使得新 向量中包含該像素塊的上下文信息。
多頭自注意力模塊包括多個并行計算的自注意 力模塊,每個自注意力模塊單獨進(jìn)行自注意力計算, 然后合并所有子空間中的注意力信息。多頭自注意 力模塊包含多組權(quán)重矩陣,可并行地從輸入像素塊 中獲取多組信息,每個注意力頭關(guān)注輸入像素塊的 不同特征。多個自注意力模塊通過按位相加得到多 頭自注意力 MultiHead:

獨立的自注意力模塊各自關(guān)注不同信息,包括 局部信息和全局信息。與單頭自注意力模塊相比, 多頭注意力模塊可獲取更加豐富的視覺信息。
2.2 Swin−Transformer 網(wǎng)絡(luò)結(jié)構(gòu)
Swin−Transformer 在 Transformer 的基礎(chǔ)上引入 滑動窗口操作,并借鑒卷積神經(jīng)網(wǎng)絡(luò)中的層次化構(gòu) 建方式。隨著網(wǎng)絡(luò)深度加深,通過跨層連接和自注意力計算來提高模型的感受野和特征提取能力。滑 動窗口操作將注意力計算限制在窗口中,能大量節(jié) 省全局自注意力計算帶來的計算開銷。
Swin−Transformer 網(wǎng)絡(luò)由多 個 Swin 塊堆疊而 成,每個 Swin 塊由 2 個連續(xù)的 SwinTransformer 塊 構(gòu)成,結(jié)構(gòu)如圖 5 所示。SwinTransformer 塊由窗口 多頭自注意力模塊(Window-basedMSA,W−MSA)和 滑動窗口多頭自注意力模塊(ShiftedWindow-based MSA,SW−MSA)組成。一個 SwinTransformer 塊(圖 5 左 半 部 分 ) 由 多 層 感 知 機(jī) (Multi-layer Perceptron, MLP) 和 W−MSA 組 成 , 在 每 個 W−MSA/SW−MSA 模塊和 MLP 之間使用正則化層(LayerNorm,LN)及 殘差連接。另一個 SwinTransformer 塊(圖 5 右半部 分)由帶高斯誤差線性單元的非線性 2 層 MLP 和 SW−MSA 組成。
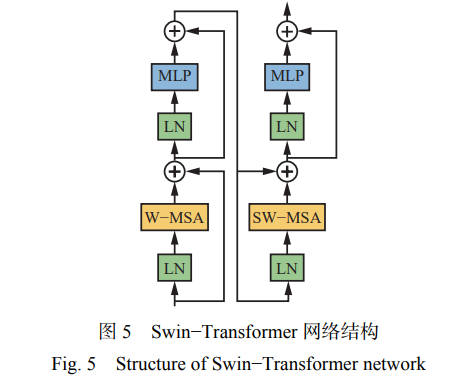
Swin−Transformer 網(wǎng)絡(luò)整體包含 4 個階段,每個 階段會將輸入特征圖的分辨率縮小一半,逐層擴(kuò)大 感受野。將 H×W(高×寬)的輸入圖像切成一個個不 重疊的大小為 4×4 的像素塊,并將每個像素塊嵌入 到通道維度,得到(H/4)×(W/4)的特征圖。每個階段 包括像素塊合并和多個 Swin 塊,在下采樣的同時特 征通道的維度擴(kuò)展 2 倍。這樣層級化的設(shè)計使得網(wǎng) 絡(luò)能夠更多地學(xué)習(xí)到全局信息。W−MSA 在每個窗 口內(nèi)進(jìn)行自注意力計算,不可避免地忽略了窗口間 的信息互動,而 SW−MSA 可解決跨窗口像素塊無法 建立信息連接的問題。在實際操作中,W−MSA 將 8×8 的特征圖劃分成不重合的 4 個窗口,每個窗口包 含 4×4 個像素塊。SW−MSA 在特征圖上進(jìn)行窗口的 循環(huán)滑動,在上一層相鄰的不重合窗口之間引入連 接,在變換后的窗口內(nèi)進(jìn)行自注意力計算。
根據(jù)自注意力計算公式可得大小為 H×W×C 的特征圖計算量:
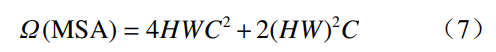
引入窗口機(jī)制后的計算量為
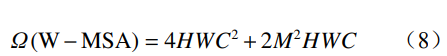
式中 M 為滑動窗口的單邊大小。
由以上分析可知,當(dāng) H 和 W 較大、M 較小時,窗 口自注意力模型的計算量遠(yuǎn)小于自注意力模型。
2.3 YOLOv5s_swin 模型
YOLOv5s 是 YOLOv5 系列目標(biāo)檢測模型中最小 的版本,專為輕量化設(shè)計,適用于資源受限的計算環(huán) 境[24]。該模型基于 CSPDarknet53 架構(gòu),通過調(diào)整 深度和寬度系數(shù),顯著降低了參數(shù)量,同時保持了較 高的推理速度,在標(biāo)準(zhǔn)測試環(huán)境下,推理延遲約為 3.6ms/幀。盡管其檢測精度略低于同系列中的其他 版本,但在 COCO 數(shù)據(jù)集上全類平均精度(mAP)仍 達(dá) 37.4%,表現(xiàn)出良好的性能平衡。YOLOv5s 的輕 量化特性使其特別適合于移動設(shè)備、嵌入式系統(tǒng)及 對實時性要求較高的應(yīng)用場景。
YOLOv5s 模型包括 3 個部分:特征提取骨干網(wǎng) 絡(luò)(Backbone)、特征融合頸部網(wǎng)絡(luò)(Neck)和檢測頭 (Detection)。本文利用 Swin−Transformer 網(wǎng)絡(luò)對傳 統(tǒng) YOLOv5s 模型進(jìn)行了改進(jìn),以進(jìn)一步提升其檢測 性能,將改進(jìn)后模型命名為 YOLOv5s_swin,其結(jié)構(gòu) 如圖 6 所示。
YOLOv5s_swin 模型的檢測過程大致分為 3 個 步 驟 : ①特征提取。將輸入圖像的比例調(diào)整 為 608×608, 并 輸 入 至 Backbone 網(wǎng) 絡(luò) 。 經(jīng) 過 Swin− Transformer 模塊輸出 3 種不同比例的特征圖,大小 分別為 76×76,38×38 和 19×19,這 3 種特征圖包含不 同的特征信息。Backbone 網(wǎng)絡(luò)中的 SPPF 模塊參照 空間金字塔的構(gòu)造原理,通過融合特征圖的局部特 征和全局特征,使得特征圖的信息更加豐富,能在一 定程度上解決目標(biāo)多尺度的問題。②特征融合。通 過 Backbone 網(wǎng)絡(luò)獲得 3 種不同尺度的特征圖并傳輸 到 Neck 網(wǎng)絡(luò),通過執(zhí)行上采樣、卷積、信道級聯(lián)等 操作,充分整合特征圖提供的信息。Neck 網(wǎng)絡(luò)采用 特征金字塔和路徑聚合網(wǎng)絡(luò)結(jié)合的結(jié)構(gòu),有利于模 型充分利用不同特征層的信息,提高對多尺度目標(biāo) 和密集目標(biāo)的檢測效果。③檢測結(jié)果輸出。Neck 網(wǎng)絡(luò)完全整合這些特征后,最終由 Detection 網(wǎng)絡(luò)輸 出 3 個尺寸分別為 76×76,38×38 和 19×19 的檢測結(jié) 果,對應(yīng)的 3 個具有不同參數(shù)的檢測頭分別用于檢 測大物體、中物體和小物體。目標(biāo)檢測任務(wù)中分類 器會得到多個候選框和候選框中目標(biāo)類別的置信 度,存在冗余結(jié)果,根據(jù)分類器得到的類別置信度進(jìn) 行排序,使用非極大值抑制操作剔除不滿足閾值條 件的冗余預(yù)測框,選出最佳結(jié)果。這種操作可增強(qiáng) 模型對多目標(biāo)和存在遮擋目標(biāo)的檢測能力,提升檢測效果。
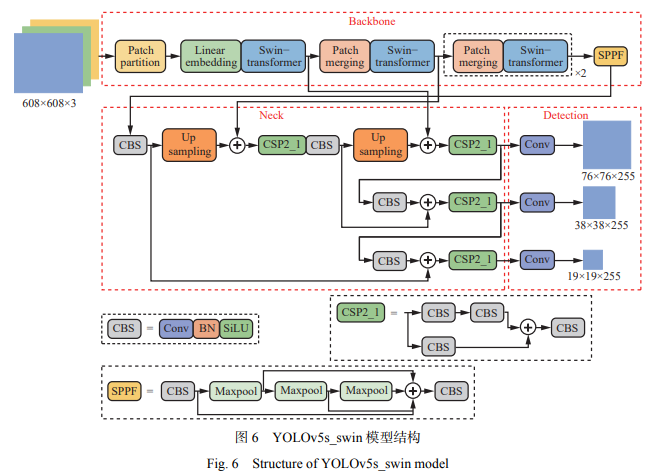
通過引入滑動窗口的操作,不僅可有效降低 Transformer 模型中全局自注意力計算的計算量,同 時可增加窗口之間的信息交互,融合圖像中的局部 信息和全局信息 ,有效提升目標(biāo)檢測的精確度。
3 基于姿態(tài)估計的井下人員行為識別
煤礦井下人員在狹長巷道中作業(yè)時,人體與攝 像機(jī)之間的距離遠(yuǎn)近交替,人體檢測框常呈現(xiàn)出多 尺度特征。針對該問題,本文在 YOLOv5s_swin 檢測 模型檢測出人體框的基礎(chǔ)上,選用多尺度特征提取 網(wǎng)絡(luò)對檢測框中行人的骨骼關(guān)節(jié)點信息進(jìn)行提取, 再將檢測框和骨骼關(guān)節(jié)點信息送入 ST−GCN 對人員 行為進(jìn)行識別和分類。
3.1 基于多尺度特征融合的人體姿態(tài)估計
檢測多尺度目標(biāo)的關(guān)節(jié)信息時需要解決 2 個難 題:①由于尺度變化較大,如何在準(zhǔn)確檢測中目標(biāo)、 大目標(biāo)人體關(guān)節(jié)點的同時提高小目標(biāo)人體關(guān)節(jié)點的 檢測精度。②如何生成更精準(zhǔn)的預(yù)測熱圖,提高小 目標(biāo)人體關(guān)節(jié)點的檢測精度。
為了解決尺度不一的問題,主流方法是引入特 征金字塔模塊進(jìn)行多尺度特征融合,但是在特征金 字塔進(jìn)行下采樣的特征融合過程中,分辨率小的小 目標(biāo)人體關(guān)節(jié)點可能已經(jīng)損失了部分語義信息,會 導(dǎo)致最終預(yù)測的關(guān)節(jié)點熱圖精度較低。因此,需要 增大輸入圖像的分辨率,但是當(dāng)分辨率增大到一定 程度時,大目標(biāo)人體關(guān)節(jié)點的檢測精度開始降低。 同時,人體的不同關(guān)節(jié)點在不同特征層上具有不同 的檢測精度。基于此,學(xué)者們設(shè)計了多尺度特征融 合網(wǎng)絡(luò),這類網(wǎng)絡(luò)可使多尺度特征充分融合,利用不 同尺度的特征信息進(jìn)行關(guān)節(jié)點熱圖預(yù)測,有效提高 關(guān)節(jié)點檢測精度。本文采用不同的高分辨率特征提 取網(wǎng)絡(luò)(High-ResolutionNetwork,HRNet)對比分析 多尺度特征融合提取效果。
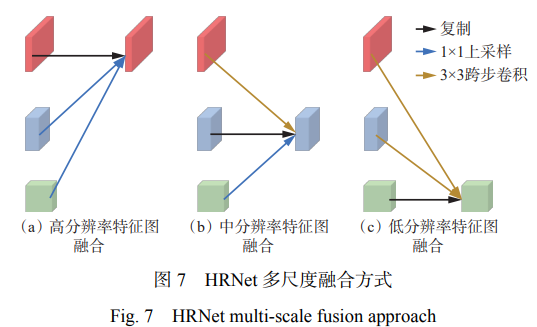
HRNet 通過并行子網(wǎng)來連接不同尺度的信息。 由于 HRNet 在提取人體骨架關(guān)節(jié)點過程中沒有復(fù)雜 的預(yù)處理環(huán)節(jié),可有效減少特征提取過程中的信息 損失,保留與實際行為高度相關(guān)的關(guān)節(jié)位置信息。 HRNet 包含多個分辨率逐漸降低的平行子網(wǎng)絡(luò),平 行的子網(wǎng)絡(luò)之間并行連接并通過多尺度信息融合進(jìn) 行信息交流。隨著網(wǎng)絡(luò)加深,模型在生成低分辨率 特征圖的同時保持高分辨率特征圖,將高分辨率和 低分辨率特征圖并行連接,可在擴(kuò)大特征感受野的 同時保留低層語義信息,交叉融合不同分辨率的特 征,即多尺度融合。
HRNet 多尺度融合方式如圖 7 所示。對分辨率 相同的特征圖執(zhí)行復(fù)制操作;對分辨率較低的特征 圖執(zhí)行最近鄰差值法上采樣操作,將低分辨率特征 圖轉(zhuǎn)換為高分辨率特征圖;對分辨率較高的特征圖 執(zhí)行跨步卷積下采樣操作,將高分辨率特征圖轉(zhuǎn)換 為低分辨率特征圖。最后將 3 種經(jīng)過處理的同分辨 率的特征圖融合。這種融合方式結(jié)合了高、中、低 語義信息,可增強(qiáng)網(wǎng)絡(luò)模型的分類能力,在二維人體 關(guān)節(jié)點檢測應(yīng)用中準(zhǔn)確度較高。
3.2 基于 ST−GCN 的行為識別
ST−GCN 通過在時間和空間序列對動態(tài)骨架進(jìn) 行建模,完成對骨骼關(guān)節(jié)點的行為識別。ST−GCN 模型建立在一系列骨架時空圖之上,骨架時空圖有 2 個維度,分別是符合人體關(guān)節(jié)自然連通性的空間維 度和在連續(xù)時間步長中連接相同關(guān)節(jié)的時間維度。 在空間維度中,每個節(jié)點表示人體骨架中的關(guān)節(jié)點, 每個邊表示同一時間關(guān)節(jié)點之間的連接關(guān)系,稱之 為第 1 類邊。時間維度中的邊表示某個關(guān)節(jié)點在各 個時間之間的連接關(guān)系,稱為第 2 類邊。在此基礎(chǔ) 上,ST−GCN 構(gòu)建了多層時空圖卷積,多層級化結(jié)構(gòu) 使得信息能夠沿著空間和時間維度進(jìn)行整合。
在空間維度上,人體在活動時骨骼關(guān)節(jié)點會產(chǎn) 生局部小范圍移動,一定區(qū)域內(nèi)所有關(guān)節(jié)點的共同 移動可引起人體產(chǎn)生某種動作。ST−GCN 對關(guān)節(jié)點 進(jìn)行動態(tài)建模時,遍歷全部關(guān)節(jié)點,按照小組的形式 將人體關(guān)節(jié)點劃分成若干個區(qū)域,構(gòu)成鄰接矩陣,再 通過卷積神經(jīng)網(wǎng)絡(luò)學(xué)習(xí)這些區(qū)域內(nèi)的特征變化,得 出動作信息。在遍歷時,遍歷的當(dāng)前關(guān)節(jié)點稱為根 節(jié)點,與該節(jié)點相連的節(jié)點稱為子節(jié)點。骨骼關(guān)節(jié) 點分區(qū)策略如圖 8 所示。

單一劃分策略將根節(jié)點和子節(jié)點全部劃分為一 個子集。基于距離劃分策略將中心節(jié)點分為一類, 鄰域節(jié)點分為另一類。基于空間配置劃分策略按照 關(guān)節(jié)點到骨骼重心的距離將關(guān)節(jié)點分為 3 類。計算 所有關(guān)節(jié)點的平均坐標(biāo)值并作為人體骨骼的重心, 再對關(guān)節(jié)點進(jìn)行分區(qū),第 t 幀第 m 個根節(jié)點下第 j 個 子節(jié)點的分區(qū)為
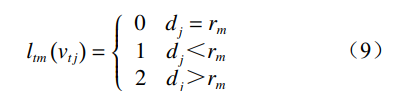
式中:dj 為子節(jié)點到骨骼重心的距離;rm 為根節(jié)點到 骨骼重心的平均距離。
當(dāng) dj=rm 時,該節(jié)點為根節(jié)點;當(dāng) dj<rm 時,該節(jié) 點稱為向心點;當(dāng) dj>rm 時,該節(jié)點為離心點。實驗 證明,基于空間配置劃分策略更能表征人體關(guān)節(jié)點 的向心運動和離心運動。
與空間維度的關(guān)節(jié)點分布不同,同一個關(guān)節(jié)點 在時間維度上是連續(xù)的,與圖像具有相同的序列信 息,因此在時間維度上可直接使用卷積神經(jīng)網(wǎng)絡(luò) 進(jìn)行學(xué)習(xí),得到同一關(guān)節(jié)點在時間維度上的動態(tài) 信息。
4 實驗結(jié)果與分析
4.1 井下人員檢測性能驗證
將檢測模型在開源的 MSCOCO 數(shù)據(jù)集上訓(xùn)練 300 個 epoch,在 MSCOCO 數(shù)據(jù)集中只選取標(biāo)簽為 “person”的樣本進(jìn)行訓(xùn)練,并將訓(xùn)練得到的模型權(quán) 重作為預(yù)訓(xùn)練權(quán)重。利用預(yù)訓(xùn)練權(quán)重,在本文構(gòu)建 的井下人員檢測數(shù)據(jù)集上進(jìn)行二次訓(xùn)練并微調(diào)模型 參數(shù),以進(jìn)一步優(yōu)化模型權(quán)重并提高檢測準(zhǔn)確率。 模型訓(xùn)練的硬件配置:處理器為 AMDRyzen95950x, 顯卡為 NVIDIA RTX3090,內(nèi)存為 32 GiB,系統(tǒng)為 ubuntu22.04,軟件開發(fā)平臺為 CUDA11.0,Python3.7。
將 YOLOv5s_swin 與 YOLOv5s 及基于無錨框的 一階段檢測模型 Centernet 進(jìn)行對比。訓(xùn)練參數(shù)設(shè)置: batch_size 為 64,迭代次數(shù)為 300,使用余弦退火策略 調(diào)整學(xué)習(xí)率,優(yōu)化器選擇 SGD。輸入圖像大小設(shè)置 為 608×608。目標(biāo)檢測模型性能比較結(jié)果見表 2。
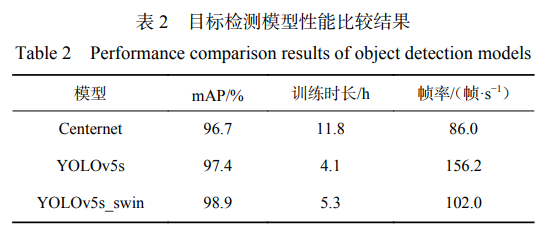
由表 2 可看出,YOLOv5s 系列的檢測模型檢測 速度高于 Centernet,訓(xùn)練時長遠(yuǎn)小于 Centernet。在 YOLOv5s 模型中引入自注意力機(jī)制后,訓(xùn)練時長比 基準(zhǔn)模型只增加了 1.2h。在精確度指標(biāo)上,YOLOv5s_ swin 在 YOLOv5s 的基礎(chǔ)上提升了 1.5%,達(dá) 98.9%, 推理速度達(dá) 102 幀/s,滿足實時性檢測要求。
模型損失函數(shù)變化曲線如圖 9 所示。可看出,YOLOv5s_swin 比 YOLOv5s 的損失值低,在 300 個 epoch 后,YOLOv5s_swin 模型的損失值已經(jīng)降低到 0.019。因此,融入自注意力機(jī)制后的檢測模型魯棒 性更好。

YOLOv5s 和 YOLOv5s_swin 模型的可視化激活 熱力圖如圖 10 所示。可視化激活熱力圖反映出神 經(jīng)網(wǎng)絡(luò)在預(yù)測目標(biāo)時關(guān)注的像素區(qū)域,即不同位置 像素點對結(jié)果的影響程度。由圖 10 可看出,相比 YOLOv5s 模型,引入自注意力機(jī)制后的檢測模型重 點關(guān)注了人體區(qū)域的像素點,減少了對于周圍環(huán)境 的關(guān)注,從而降低了環(huán)境對目標(biāo)檢測的影響,進(jìn)而提 升了網(wǎng)絡(luò)檢測精度。

4.2 姿態(tài)估計性能驗證
根據(jù)并行分支的特征通道數(shù)不同,高分辨率特 征提取網(wǎng)絡(luò)可分為 HRNet_w32 和 HRNet_w48。這 2 個版本的網(wǎng)絡(luò)模型分別在 MSCOCO 姿態(tài)估計數(shù) 據(jù)集上訓(xùn)練和測試。對人體關(guān)節(jié)點提取器訓(xùn)練 300 個 epoch,輸入圖像尺寸固定為 384×288。模型 使用 Adam 作為優(yōu)化器,初始學(xué)習(xí)率設(shè)置為 0.0001, 為防止模型出現(xiàn)過擬合的情況,第 200 個 epoch 及之 后的學(xué)習(xí)率設(shè)置為 0.00001。
選用經(jīng)典的自上而下的姿態(tài)估計網(wǎng)絡(luò) Alphapose 與高分辨率特征提取網(wǎng)絡(luò)進(jìn)行對比實驗,并使用 mAP、 平均目標(biāo)關(guān)鍵點相似度 (Average Precision, APOKS=0.50)、中等目標(biāo)平均預(yù)測正確率 APM 和大目標(biāo) 平均預(yù)測正確率 AP L 作為評價指標(biāo),實驗結(jié)果見表 3。
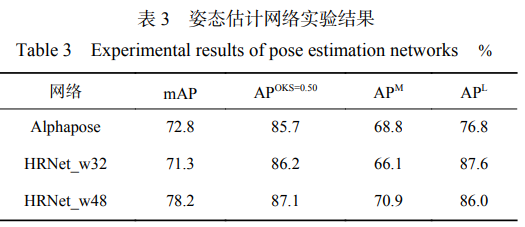
由表 3 可看出,高分辨率特征提取網(wǎng)絡(luò)對人 體關(guān)節(jié)點的提取精度比其他姿態(tài)估計網(wǎng)絡(luò)高,能 夠準(zhǔn)確提取不同尺度的目標(biāo)人體關(guān)節(jié)點。隨著特征 通道數(shù)的增加,HRNet_w48 網(wǎng)絡(luò)比 HRNet_w32 網(wǎng)絡(luò) 的 mAP 高 0.97%,其中 HRNet_w48 對中等目標(biāo)人體 的檢測精度達(dá) 70.9%,對大目標(biāo)人體的檢測精度達(dá) 86.0%,平均精度達(dá) 78.2%,平均目標(biāo)關(guān)鍵點相似度超 過 87%。
針對煤礦井下環(huán)境,高分辨率特征提取網(wǎng)絡(luò)對 人體關(guān)節(jié)點的提取效果如圖 11 所示。由圖 11(a)可 知,HRNet_w32 網(wǎng)絡(luò)誤將環(huán)境背景識別成人體的一 部分。在相同場景下,HRNet_w48 網(wǎng)絡(luò)消除了這種 誤檢的情況,說明 HRNet_w48 網(wǎng)絡(luò)比 HRNet_w32 網(wǎng) 絡(luò)在人體骨架特征提取方面更具優(yōu)勢,同時對環(huán)境 的抗干擾能力更強(qiáng)。

4.3 行為識別性能驗證
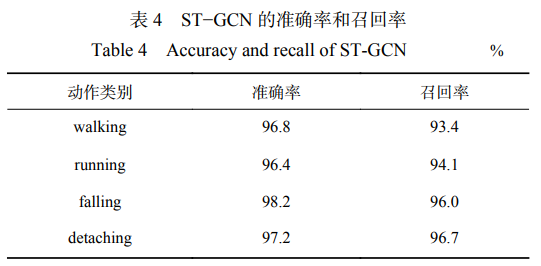
選擇 Adam 作為優(yōu)化器,設(shè)置 batch_size 為 16, 學(xué)習(xí)率為 0.001,模型訓(xùn)練 60 個 epoch。ST−GCN 識 別各動作類別的準(zhǔn)確率和召回率見表 4。可看出, ST−GCN 的準(zhǔn)確率和召回率都較高,可準(zhǔn)確地對礦工 行為進(jìn)行分類。測試模型的推理速度可達(dá) 31幀/s, 滿足井下監(jiān)測需求。
YOLOv5s_swin+HRNet+ST−GCN 模型的行為識 別結(jié)果如圖 12 所示。可看出,在復(fù)雜工礦條件下, 模型可準(zhǔn)確檢測并識別出工作人員的具體行為,同 時克服圖像背景的干擾。

5 結(jié)論
1)采用自上而下的策略,構(gòu)建了一種基于自注 意力機(jī)制的目標(biāo)檢測模型 YOLOv5s_swin,以更加準(zhǔn) 確、高效地提取人體關(guān)節(jié)信息。針對井下人員與監(jiān) 控探頭間距不定導(dǎo)致的人體檢測框多尺度變化問 題,在檢測出人員目標(biāo)的基礎(chǔ)上,使用高分辨率特征 提取網(wǎng)絡(luò)對人體的關(guān)節(jié)點進(jìn)行提取,再通過 ST− GCN 進(jìn)行行為識別。
2)實驗結(jié)果表明:YOLOv5s_swin 的精確度達(dá) 98.9%,在 YOLOv5s 的基礎(chǔ)上提升了 1.5%,推理速度 達(dá) 102 幀/s,滿足實時性檢測要求;高分辨率特征 提取網(wǎng)絡(luò)能夠準(zhǔn)確提取不同尺度的目標(biāo)人體關(guān)節(jié) 點,特征通道數(shù)更多的 HRNet_w48 網(wǎng)絡(luò)性能優(yōu)于 HRNet_w32;在復(fù)雜工礦條件下,ST−GCN 模型的準(zhǔn) 確率和召回率都較高,可準(zhǔn)確地對礦工行為進(jìn)行分 類,推理速度達(dá) 31幀/s,滿足井下監(jiān)測需求。
