計算機工程與科學投稿論文格式參考:基于便箋式存儲器的向量化SpMV算法的性能評估與分析 *
關鍵詞:稀疏矩陣向量乘;便箋式存儲器;CSR;ARM SVE
作者:張宗茂;董德尊;王子聰;常俊勝;張曉云;王紹聰
作者單位:國防科技大學
阿斯頓發順豐的
1 引言
稀疏矩陣向量乘 SpMV (Sparse Matrix Vector Multiplication) 是矩陣向量運算的一種特殊形式。其主要操作是執行y=y+Ax運算其中 A 是稀疏矩陣,x 和 y 分別是稠密輸入和輸出向量 是稀疏線性運算的重要內核函數,廣泛應用于高性能計算、人工智能、大數據等領域。SpMV 是高性能計算領域基準測試程序 HPCG (High Performance Conjugate Gradient) 代碼中的重要組成部分,也是圖計算庫 GraphBLAS 的必備計算內核。
稀疏矩陣中大量的零元素給存儲和計算帶來了極大的挑戰。為了降低稀疏矩陣存儲開銷并加速 SpMV 計算,研究人員提出了多種稀疏矩陣存儲格式。除了 COO (COOrdinate)、CSR (CompressedSparseRow)、DIA (DIAgonal) 和 ELL (ELLPACK) 等稀疏矩陣基本存儲格式外,研究人員基于這些基本存儲格式開發了很多新的存儲格式,如 BCCOO (Blocked Compressed common COOrdinate)、CSB (Compressed Sparse Block)、SELL (Sliced ELLPACK) 等,針對不同的計算平臺和處理器體系結構狀態以提升 SpMV 算法執行過程中數據局部性,從而提升 SpMV 算法性能。此外,為了對 SpMV 進行高效向量化,文獻 [6] 提出了 CSR5 存儲格式。Regnault 等人提出了 SPC5 格式,并借助 Intel AVX-512 對 SpMV 進行向量優化。文獻 [8] 提出適合向量化的矩陣存儲格式 CVR (Compressed Vectorization-oriented sparse Row),該格式可以同時處理稀疏矩陣的多行,并將其分成多個單指令多數據 SIMD (Single Instruction Multiple Data) 通道,以利用現代處理器中的向量部件。但是,大多數改進的矩陣存儲格式會引入額外的矩陣存儲格式轉換開銷。
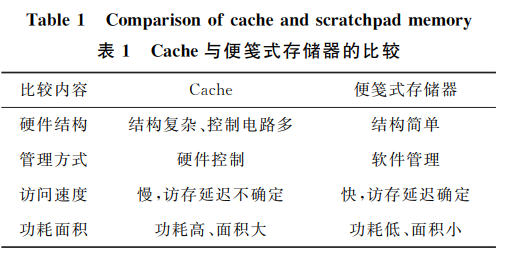
便箋式存儲器 SPM (ScratchPadMemory) 是一種結構簡單、訪存延遲固定、功耗低、面積小的片上高速存儲器,被廣泛應用在嵌入式處理器、GPU 和各類加速器中。IBM CELL 處理器用便箋式存儲器代替部分片上 Cache,以降低處理器功耗和面積開銷。GPU 中的共享內存 SM (Shared Memory) 本質上也是便箋式存儲器。與完全由硬件控制的 Cache 不同,便箋式存儲器由軟件管理。在計算機系統中,便箋式存儲器和內存統一存儲空間編址,應用開發人員可以根據應用程序的特征和需要,在程序中直接對便箋式存儲器進行數據分配,以降低程序執行過程中的訪存沖突,從而提升程序執行效率。
隨著 Moore 定律和 Dennard 縮放定律的失效,計算機系統難以通過簡單增加處理器上晶體管數量和提升處理器時鐘頻率進一步提升性能。因此,計算機體系結構研究人員和軟件開發人員利用并行化提升處理器性能和應用程序執行效率。指令級并行 ILP (Instruction Level Parallelism) 和線程級并行 TLP (Thread Level Parallelism) 已經被廣泛用于提升系統性能,如流水線、Tomasulo 算法和同時多線程 SMT (Simultaneous MultiThreading) 等機制 。此外,數據級并行 DLP (Data Level Parallelism) 可以通過向量運算能力和單指令多數據 SIMD 進一步提升處理器性能和能效。許多應用程序通過數據級并行,借助處理器的向量執行能力可以極大程度提升應用程序性能,但其執行效率與代碼向量化的質量密不可分。
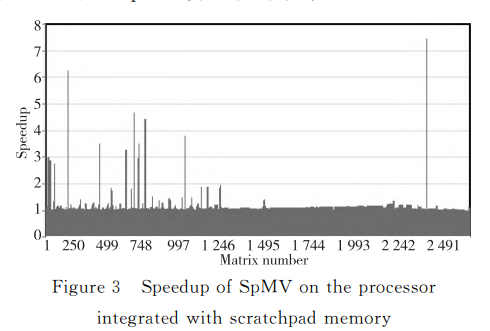
SpMV 是訪存密集型應用程序,由于矩陣的壓縮存儲,在計算過程中大量的間接訪存和對稠密輸入向量 x 的不規則訪存不僅使得性能受限,而且很難高效向量化。便箋式存儲器是一種軟件控制的片上高速存儲器,因此,可以將 SpMV 執行過程中的輸入向量存放在便箋式存儲器中,以改善計算過程中的訪存沖突。隨著數據級并行在通用處理器中的大量應用,對應用程序進行向量化優化可以顯著提升程序執行效率。本文使用 ARM SVE (Scalable Vector Extension) 對基于 CSR 格式的 SpMV 算法進行向量化;基于 gem5 模擬器實現便箋式存儲器及其軟件訪問接口,以評估便箋式存儲器對向量化 SpMV 算法性能影響。本文對稀疏矩陣庫 SuiteSparse Collection 中 2562 個真實應用矩陣進行測試。實驗結果表明,集成了便箋式存儲器的處理器與傳統多級 Cache 處理器相比,針對向量化 SpMV 算法能夠實現的最大加速比為 7.45,平均加速比為 1.11。
2 研究背景
本節對稀疏矩陣基本存儲格式及其 SpMV 算法、便箋式存儲器結構和 ARM SVE 進行介紹。
2.1 稀疏矩陣存儲格式與 SpMV 算法
由于稀疏矩陣中存在大量的零元素,故如何高效存儲稀疏矩陣是 SpMV 計算首先需要解決的問題。過去幾十年,研究人員根據不同的應用需求和特性提出了很多稀疏矩陣存儲格式,但 CSR 存儲格式仍然是當前最通用的矩陣存儲格式,許多矩陣計算庫和線性計算庫都是基于 CSR 實現,如 Eigen、Taco 和 IntelMKL (Math Kernel Library) 等。
COO 矩陣存儲格式是稀疏矩陣最簡單的一種壓縮存儲格式 ,采用 data、row_ptr 和 col_idx 3 個一維數組分別存儲矩陣非零元數值、非零元行號和列號。COO 格式對應的 SpMV 算法如算法 1 所示。COO 格式適用于任意結構的稀疏矩陣,其 SpMV 算法實現簡單,但缺點是會存儲大量重復值,導致存儲效率不高。

CSR 格式是當前應用最廣泛的矩陣存儲格式。CSR 格式使用 data、row_ptr 和 col_idx 3 個一維數組存儲稀疏矩陣。其中,data 用于存儲矩陣非零元值,col_idx 用于存儲矩陣非零元的列索引,row_ptr 用于存儲矩陣每行非零元的起始位置。該格式最大的優點是壓縮率高,存儲開銷小,對矩陣的結構和非零元分布不敏感,通用性好,適用于絕大多數應用場景。CSR 格式對應的 SpMV 算法如算法 2 所示。該算法對輸入向量 x 的大量間接訪問導致其數據局部性較差且向量化效率低。

2.2 便箋式存儲器
便箋式存儲器是一種訪存延遲固定的快速隨機訪問的片上存儲設備。便箋式存儲器由譯碼單元、存儲陣列和列電路 3 個部分構成,數據直接存放在存儲陣列中,不需要額外的部件進行標識。與片上 Cache 相比,便箋式存儲器沒有復雜的數據失效、臟行替換和寫回等機制,因此不需要用額外的 Tag 體存儲標簽位,其功耗和面積顯著低于 Cache。
便箋式存儲器最大的特點是具有獨立的地址空間,與計算機系統主存統一存儲空間編址。因此,研究人員可以直接對其進行讀寫控制,在程序中實現對便箋式存儲器的數據分配,從而改善數據局部性,提升程序性能。Cache 和便箋式存儲器特點比較如表 1 所示。
2.3 ARM SVE
SVE 是 ARM 針對高性能計算需求提出的第 2 代高級 SIMD 擴展,是面向高性能計算負載開發的一組新的向量指令。與 AVX 和 AVX512 等向量長度固定的指令集相比,SVE 是向量長度不可知 VLA (Vector Length Agnostic) 的指令集,其向量寄存器大小是可變的,范圍為 128~2048bit。
SVE 中主要包含 4 類寄存器:32 個大小可變的數據寄存器 Z0~Z31,用于存儲向量數據;16 個斷言寄存器(P 0 ~ P 15)用于標識數據寄存器中哪些數據參與運算;控制寄存器,即 FFR (First Fault Register) 寄存器和 ZCR_Elx 寄存器。
要在程序中使用 SVE 指令,有以下幾種方法: (1) SVE 優化庫:直接調用 ARMPerformance Libraries 等優化庫,其特點是使用方便,但靈活性較差。 (2) 內聯匯編:直接在代碼中添加 SVE 匯編指令,但編程難度大,程序可讀性差。 (3) SVE intrinsic:ACLE (ARM C Language Extension) 中將 SVE 向量指令封裝成函數的形式供用戶使用。這種方法只需調用相應 intrinsic 函數即可,編程簡單,代碼可讀性強。本文采用這種方式對 SpMV 算法進行向量化優化。
3 基于便箋式存儲器的 SVE 向量化 SpMV 算法優化
本節將闡述便箋式存儲器在 gem5 模擬器中的模擬實現,以及基于便箋式存儲器的向量化 SpMV 算法優化實現。
3.1 基于 gem5 的便箋式存儲器實現
在 gem5 模擬器中,處理器內存系統通過其定義好的存儲模型以及相關接口實現,因此可以借助已有存儲模型設置便箋式存儲器的特征參數,如大小、帶寬和訪問延遲等。然后再通過 gem5 中連接不同組件的端口將便箋式存儲器和處理器與其他組件進行連接即可。
在通用處理器中,CPU 和 Cache 通過總線直接與內存和外設連接,便箋式存儲器也是通過總線和處理器的其他部件進行數據交互。在 gem5 模擬器中,CPU 模型中的片上存儲設備通過無延遲的 crossbar 與各組件的對應端口進行連接。
本文提出的便箋式存儲器基于 gem5Classic 內存模型,創建了 SPM_Xbar 用于與處理器中存儲部件連接。將便箋式存儲器側端口和 SPM_Xbar 處端口進行連接,實現了處理器的存儲系統擴展。為了實現便箋式存儲器與 CPU 間的數據傳輸,CPU 側新增的端口與 SPM_Xbar 連接以搭建 CPU 和便箋式存儲器間數據通路,其實現如圖 2 所示。
便箋式存儲器和內存統一編址,要在程序中實現對便箋式存儲器的訪問與控制,需要提供便箋式存儲器的訪問接口。本文使用的便箋式存儲器分配接口函數原型為void*spm_mem_alloc (uint64_t mem_size,uint64_t mem_address),其中,mem_

size 表示便箋式存儲器的存儲空間容量,mem_address 表示便箋式存儲器在內存地址空間中的起始地址。該函數的實現是通過 mmap 系統調用函數將便箋式存儲器的存儲空間映射到統一內存地址,返回指向便箋式存儲器的指針。在程序中調用該接口會返回一個任意類型指針,通過對返回的指針進行讀寫操作實現對便箋式存儲器的訪問與控制。
3.2 基于 CSR 格式的 SpMV 算法的 SVE 向量化
本文借助 ARM 提供的 SVE intrinsics 函數對基于 CSR 存儲格式的 SpMV 算法進行 SVE 向量化,如算法 3 所示。

其中,svsum、val、idx 和 svx 是數據寄存器,分別用于存儲計算中間結果、矩陣非零元值、非零元列索引和輸入向量 x 部分值;pg 是斷言寄存器,用于標識寄存器中哪些數據會參與運算。在加載向量 x 的值時由于需要從多個不同位置獲取對應數據,因此需要借助非零元列索引,使用 gather 指令獲取數據。當矩陣一行非零元計算完成后,使用 scatter 指令對 svsum 寄存器中的數據進行歸約操作并將其寫回輸出向量 y 對應位置。
4 實驗與結果分析
在本節中使用 gem5 全系統模擬器評估基于 CSR 的向量化 SpMV 算法在集成了便箋式存儲器的處理器中的性能。
4.1 模擬系統配置
本文在 gem5 中擴展并實現了便箋式存儲器,并使用順序 CPU 模型對 ARMv8 單核處理器進行模擬,采用 gem5 全系統執行模式,將 SpMV 算法執行過程中不規則訪問的輸入向量 x 存放在便箋式存儲器中。模擬系統使用的內核為 Linux 4.18,操作系統為 Ubuntu 16.04。模擬處理器的系統配置如表 2 所示。

4.2 數據集
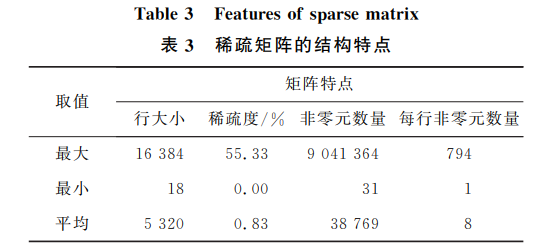
為了分析基于 CSR 的向量化 SpMV 算法性能提升,受限于便箋式存儲器實驗配置 (128 KB,即最多存儲 16 384 個雙精度浮點數),本文選擇 SuiteSparse Market Collection 數據集中行數不超過 16 384 (即 2^14) 的 2 562 個稀疏矩陣進行測試。
本文測試的稀疏矩陣均來自真實應用程序,涵蓋了圖計算、計算流體力學、網絡圖、機器學習和電路模擬等多個應用領域。所用稀疏矩陣的結構特點如表 3 所示。
4.3 實驗結果分析
SVE 向量化的 SpMV 算法在集成便箋式存儲器的處理器中的加速比如圖 3 所示。與傳統處理器相比,集成了便箋式存儲器的處理器能夠實現的最大加速比為 7.45,平均加速比為 1.11。在傳統處理器中,SpMV 算法在執行過程中首先需要執行加載指令獲取矩陣非零元列索引,然后再通過 gather 指令獲取計算所需的輸入向量值。由于矩陣非零元分布不規律,data 數組中的連續非零元間的列索引值差值通常較大,使得 gather 指令執行過程中會頻繁發生 Cache 失效,從而降低了 SpMV 算法執行效率。另外,Cache 失效處理的
延遲不固定,對 SpMV 算法性能也有較大影響。在集成了便箋式存儲器的處理器中輸入向量 x 存儲在便箋式存儲器中,當獲取到矩陣非零元列索引后,使用 gather 指令將所需數據從便箋式存儲器傳輸到向量寄存器該方法避免了向量 x 的不規則訪問,顯著降低了計算過程中的訪存沖突,從而提升了 SpMV 算法執行效率。
為了更加詳細地分析便箋式存儲器在不同特征矩陣下 SpMV 算法的性能影響,本文對測試的 2562 個矩陣,根據 SpMV 算法獲得的加速比進行劃分,分成 4 個組,編號為 1~4,不同矩陣的基本特征如表 4 所示。
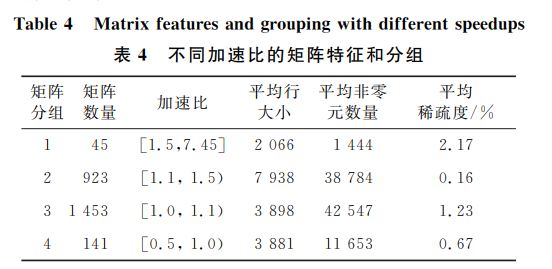
在集成便箋式存儲器的處理器中執行 SpMV 算法,加速比超過 1.5 的矩陣共 45 個,占比 1.76%。組 1 矩陣的特點是:矩陣行數最大為 13332,非零元最大數量為 5472,稀疏度最大為 15.52%。矩陣非零元數量小,非零元分布比較規律,如表 5 編號 1 的 2 個矩陣,能夠實現最高的 SpMV 加速比。
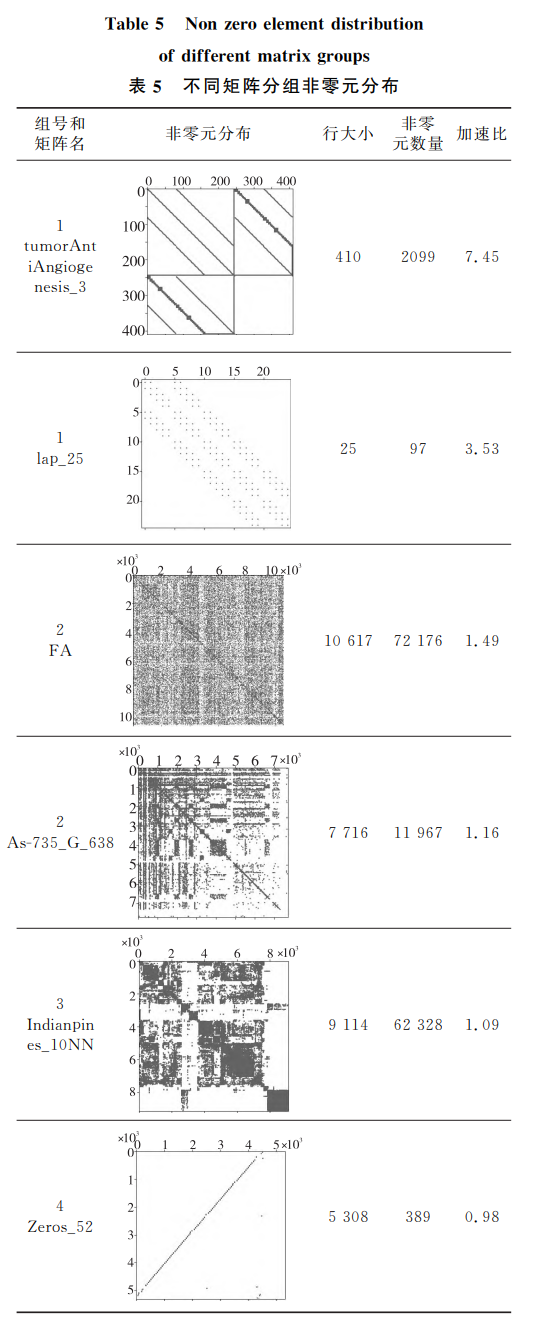
此外,在傳統多級 Cache 處理器中,Cache 缺失的延遲不固定,而在集成便箋式存儲器的處理器中對輸入向量 x 的訪問由便箋式存儲器完成訪存沖突更小,因此能夠實現更高的加速比。稀疏度超過平均值的 24 個矩陣,其矩陣規模較小,矩陣行數平均為 62,平均每行有 2 個非零元,可以通過一條 SVE 計算指令處理一行矩陣元素,能夠進一步減小對結果向量 y 的訪存開銷對于另外個矩陣,雖然矩陣規模更大,但非零元的分布非常均勻,使得計算過程中訪存沖突較少,因而該組矩陣性能最好。
組 2 矩陣數量為 923,占比 36%。該組矩陣的規模比組 1 的更大,矩陣稀疏程度有較大差異。能夠實現較好加速比是因為這些矩陣的非零元分布相對均勻,計算過程中,訪存沖突相對較小,能夠實現較好的加速比。相比于組 1,其矩陣規模更大,計算過程中訪存沖突更多,因而其性能較差。
組 3 矩陣數量為 1453 個,占比 56.7%。該組矩陣的特點是矩陣規模相對較小,但非零元數量遠大于其他組。每行非零元數量平均為 11,非零元分布非常不規律,讀取非零元列索引會頻繁引發 Cache 行替換,降低了處理器的吞吐量,從而影響 SpMV 算法性能。
組 4 矩陣數量為 141,占比 5.5%。該組矩陣的特點是矩陣規模較大,非零元數量小,非零元分布不規律。除了非零元分布不規律導致計算過程的訪存開銷外,該組矩陣存在的大量空行 (非零元數量遠小于矩陣行數矩陣數量為 54) 對結果向量寫回造成更多 Cache 行替換,從而影響 SpMV 執行效率。
為了進一步分析便箋式存儲器對不同應用領域下 SpMV 算法的加速效果,本文將測試矩陣按照所屬應用類別進行劃分。所有測試的 2562 個矩陣共包含 99 個應用類別,矩陣數量超過 20 個的應用類別共 17 個,矩陣總數為 2221,其比例為矩陣總量的 86.69%,不同類別矩陣的基本特點如表 6 所示。
不同應用類別對應基于 CSR 格式的向量化 SpMV 算法在集成便箋式存儲器的通用處理器中的平均加速比如圖 4 所示。17 個應用類別中,AG_Monien 平均加速比最大,為 1.61;加速比最小為 1.02,屬于 Pajek 應用類別;平均加速比為 1.12。AG_Monien 中大多數矩陣結構比較規整,矩陣中每行連續非零元列索引差值較大。在傳統多級 Cache 處理器中,SpMV 算法執行過程中會頻繁發生 Cache 缺失,將計算過程中經常訪問的稠密向量存放在便箋式存儲器中,可以顯著降低計算過程中的訪存沖突,能夠實現最高加速比。
Pajek 中的矩陣來源于不同領域的圖,其數據分布沒有明顯的結構特征,矩陣每行非零元分布相對均勻,計算過程中訪存沖突較小。因此,傳統多級 Cache 處理器與集成便箋式存儲器的處理器相比,其性能差異較小,從而導致具有最小加速比。
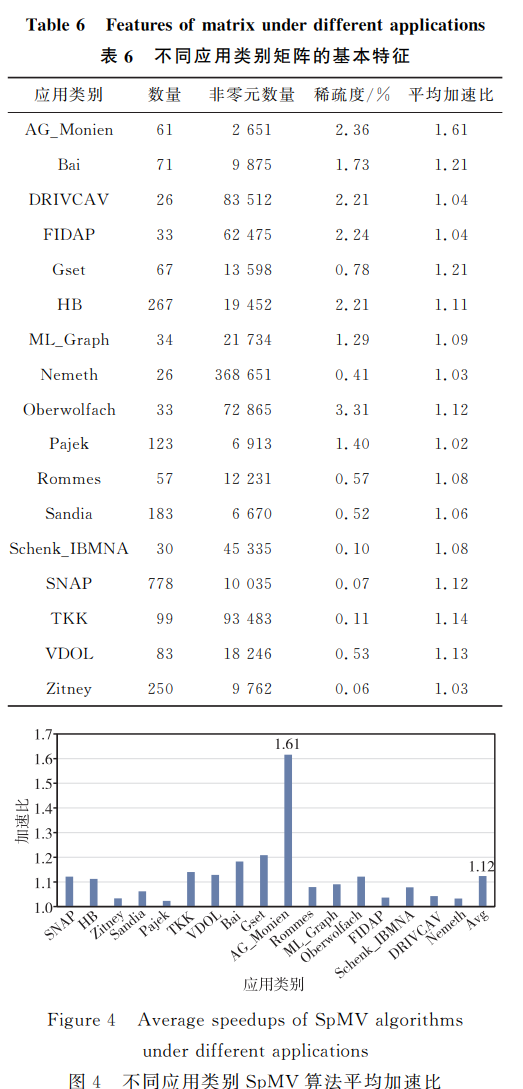
實驗數據表明,在通用處理器中集成便箋式存儲器能夠有效緩解 SpMV 算法執行過程中的訪存沖突,從而提升 SpMV 算法執行效率。但是,SpMV 算法性能與矩陣的稀疏結構、非零元分布也密切相關。由于便箋式存儲器對不同應用領域的加速效果有顯著差異,因此在加速 SpMV 算法執行過程中,還可以根據應用領域的特征,對矩陣存儲格式進行改進,以改善數據局部性,從而更好地利用便箋式存儲器,加速 SpMV 算法。
5 結束語
SpMV 是高性能計算、人工智能和大數據等領域中非常重要的內核函數。在傳統多級 Cache 處理器中計算對稠密輸入向量 x 的不規則訪存會頻繁導致 Cache 失效,從而影響 SpMV 算法執行效率。便箋式存儲器是一種結構簡單、訪存延遲固定且軟件可控的片上高速存儲器,和處理器內存統一編址,具有用戶可以直接控制的存儲空間。為了改善 SpMV 算法執行過程中的訪存沖突,本文利用便箋式存儲器對 SpMV 算法進行了優化。為了進一步提升 SpMV 算法執行效率,本文對基于 CSR 格式的 SpMV 算法進行了向量化優化。本文使用 gem5 全系統模擬器對 SuiteSparse Matrix Collection 數據集中的 2562 個稀疏矩陣進行測試與分析。實驗結果表明,集成了便箋式存儲器的處理器與傳統多級 Cache 處理器相比,針對向量化 SpMV 算法能夠實現的最大加速比為 7.45,平均加速比為 1.11。
